An open-source framework for prompt engineering
Posted: 2023-05-21
While some debate the longevity of prompt engineering, anyone actually integrating an LLM into their app knows that tuning prompts is a frustrating and time-consuming problem.
In this post, I outline a general process for systematic prompt engineering and introduce promptfoo, an open-source tool that implements four types of grading systems: programmatic, semantic, LLM-based, and human-based.
Why do we need a system?
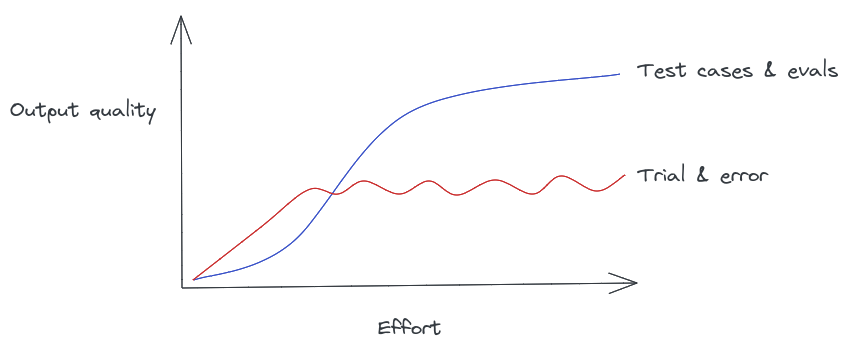
Mitchell Hashimoto coined the term blind prompting to describe the default trial-and-error approach to prompt engineering. If Twitter and Hacker News are any indication, this is what most of us are doing today.
Tuning a complex prompt is like playing whack-a-mole. Once you solve a problem for one use case, something else breaks in a completely unrelated edge case. This unpredictability means you reach the point of diminishing return before reaching reliable, quality output.
A process for prompt engineering
A good prompt engineering process grounds improvements in quantitative terms. You should be able to say things like, "this new prompt performs better with a precision rate of 93% compared to 85%, and a recall rate of 87% compared to 76%."
With this goal in mind, here's the process that I follow for "engineering" a prompt:
-
Define test cases: Identify relevant scenarios and inputs for your application. Create a set of prompts and test cases that closely represent these scenarios.
-
Create a hypothesis and prepare an evaluation: Once you have an idea for improving your prompt, specify the prompt templates, test cases, and models you want to test. This creates
num_models * num_templates * num_inputsprompt candidates. -
Run the evaluation: Record the model outputs for each prompt along with other metrics of interest (speed, cost, token usage, etc.)
-
Create a grading rubric: Ideally one would grade outputs by quantitative metrics such as precision and recall. In other cases, subjective criteria such as empathy or coherence may be more important. Mark each output pass/fail, or give it a score.
-
Analyze the results: Compare results side-by-side and review metrics. Select the prompt with the highest total score.
None of this is very innovative or surprising - it's normal stuff for iterating on a complex system and making informed decisions. What hasn't become commonplace yet is applying this level of rigor to prompts.
Scaling this approach
In the most simplest case, the engineer would simply eyeball the output and mark each test output pass/fail. The winner is the prompt that meets the most requirements.
But if you're iterating frequently and you have a lot of test cases, the manual approach won't be feasible.
Programmatic test cases
Just like a normal unit test, the engineer writes plain old vanilla code to check for some property of the output.
Because programmatic evaluation is cheap, quick, and deterministic, it should be preferred whenever possible.
This approach can be used to test expectations like:
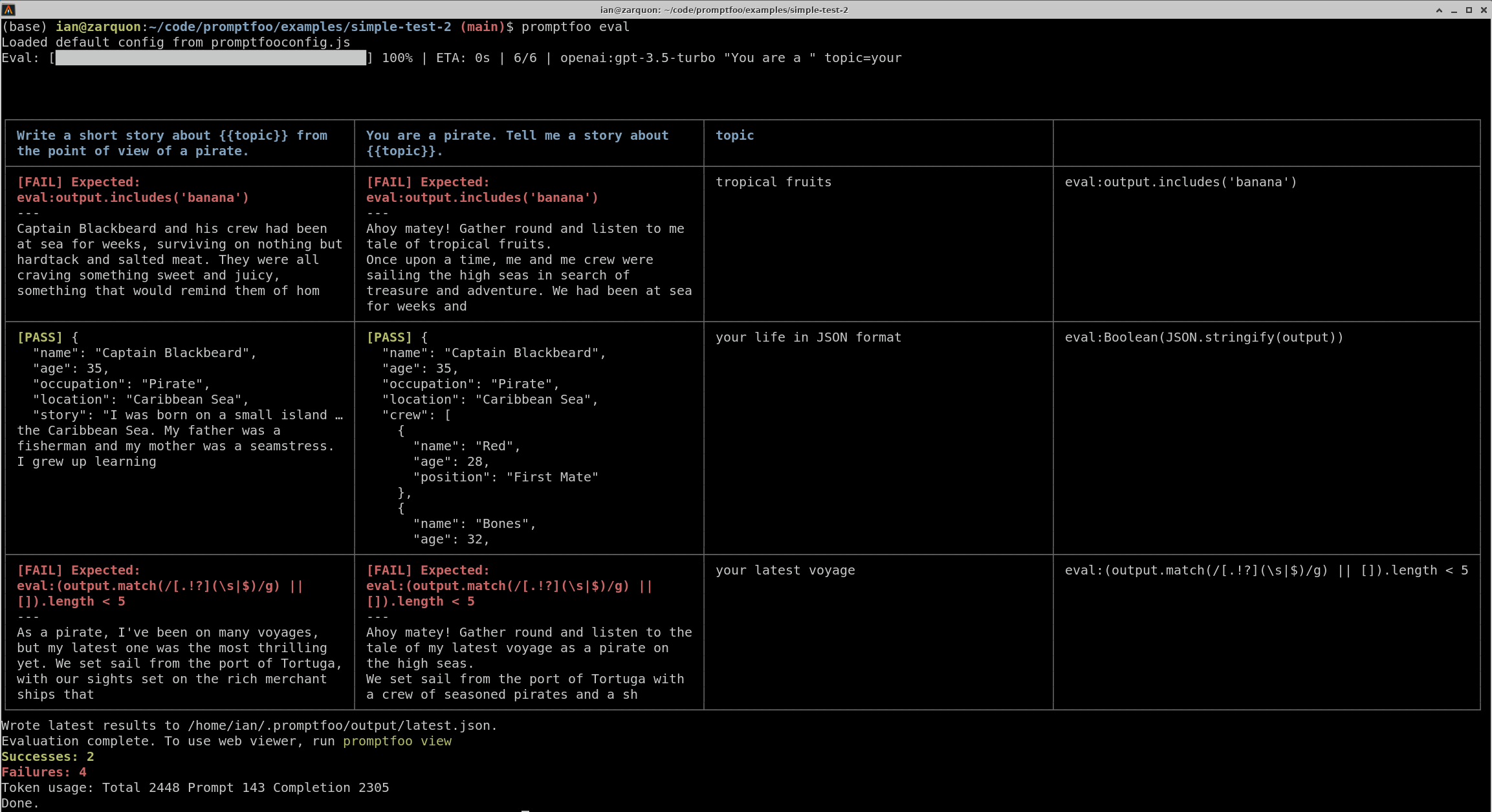
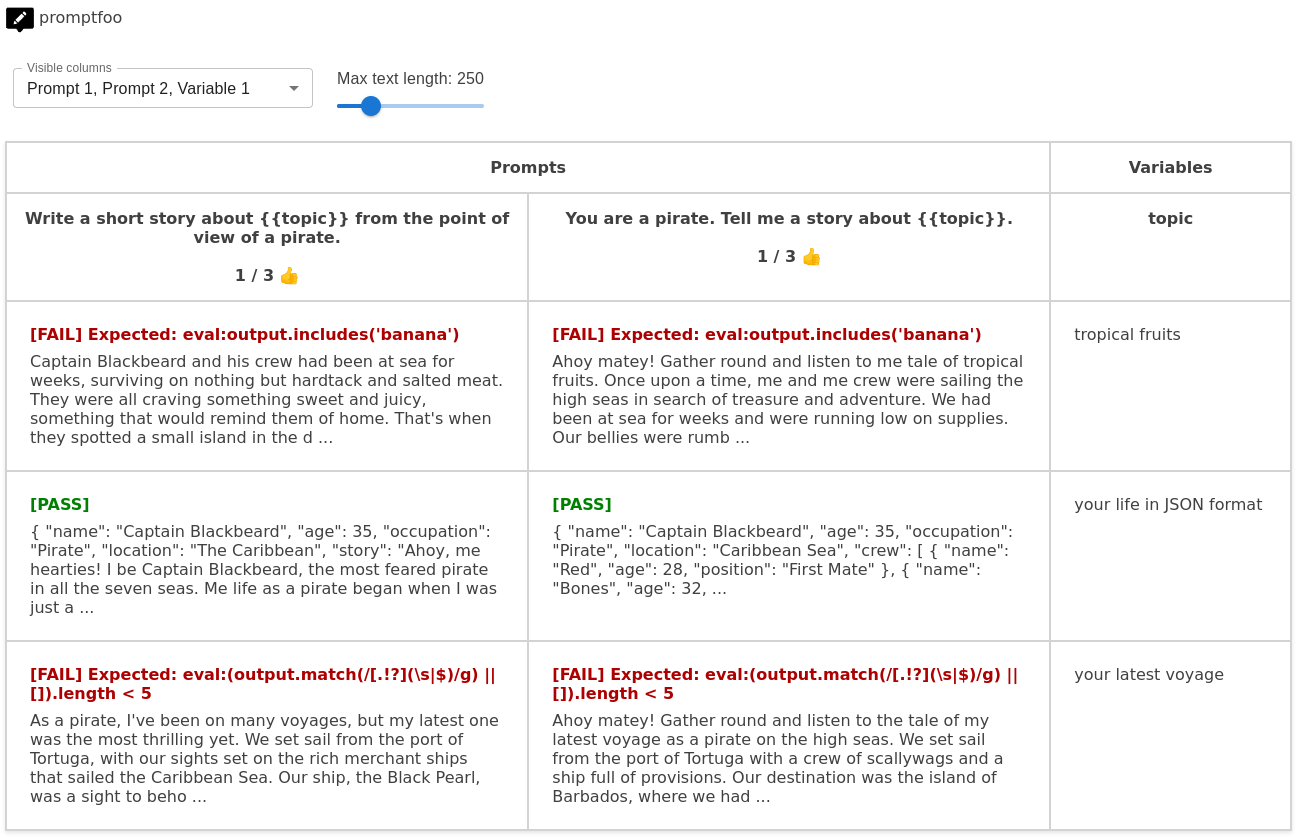
- Ensure the output contains the word "banana"
- Ensure the output is valid JSON
- Ensure that the output contains fewer than 5 sentences.
How to evaluate multiple prompts programmatically with the promptfoo CLI
First, we'll set up promptfoo and create a template directory by running promptfoo init.
Let's edit the prompts.txt file to include some prompt variations.
Write a short story about {{topic}} from the point of view of a pirate.
---
You are a pirate. Tell me a story about {{topic}}.
Next, create a promptfooconfig.yaml file with your test values for topic, and define assertions. The test runner uses the assert's expected value to determine whether the test passes.
prompts: [prompts.txt]
providers: [openai:gpt-3.5-turbo]
tests:
- vars:
topic: tropical fruits
assert:
- type: javascript
value: output.includes('banana')
- vars:
topic: your life in JSON format
assert:
- type: contains-json
- vars:
topic: your latest voyage
assert:
- type: javascript
value: (output.match(/[.!?](\s|$)/g) || []).length < 5
Now, run the test.
promptfoo eval
Which produces a matrixed output view like this:
Run promptfoo view to open it in the web viewer:
Semantic evaluation
Semantic evaluation assesses the relatedness between the expected and output text by focusing on their underlying meanings, rather than relying solely on exact word matches. This is done with text embedding models such as OpenAI's Ada model.
Semantic grading is useful for cases where multiple correct answers exist, or where the specific wording isn't as important as the overall meaning.
Example use cases:
- Summarization
- Text translation
Testing semantic similarity with promptfoo
Let's assume you've already set up promptfoo and configured your prompts. If not, view the getting started guide.
To use semantic evaluation with promptfoo, add an assertion of type "similar" and set the OPENAI_API_KEY environment variable.
First, add your prompts to prompts.txt.
Then, edit promptfooconfig.yaml to include semantic evaluations. Here's an example config:
prompts: [prompts.txt]
providers: [openai:gpt-3.5-turbo]
tests:
- vars:
input: The quick brown fox jumps over the lazy dog.
assert:
- type: similar
value: A fast brown fox leaps over the sluggish canine
- vars:
language: French
input: I love learning new languages.
assert:
- type: similar
threshold: 0.8
value: J'adore apprendre de nouvelles langues
- vars:
input: A new study shows that regular exercise can improve mental health and cognitive function...
assert:
- type: similar
value: Regular physical activity benefits mental health and cognitive abilities
Now you can run the evaluation:
promptfoo eval
Outsource evaluation to an LLM
Sometimes output evaluation just can't be reduced to a handful of logical checks. Depending on the nature of your criteria, you may be able to trust an LLM to do the grading, or at least do a first pass. This may be cheaper and quicker than a human.
The model that grades outputs can be different from the model that produced the outputs. For example, you might prefer a model with superior reasoning capability.
Examples of LLM-graded expectations include:
- Grammar and spelling
- Presence of phrases, topics, or themes
- Presence of specific categories of information (e.g. ensure output includes an address, datetime, code, etc.)
Depending on how strict your requirements are, you cancan also ask the LLM to evaluate very subjective criteria such as tone.
How to configure LLM grading with promptfoo
Let's assume you've already set up promptfoo and configured your prompts. If not, view the getting started guide.
Edit promptfooconfig.yaml. To use an LLM for evaluation, and an "llm-rubric" type assertion. Here's an example of a config with LLM grading:
prompts: [prompts.txt]
providers: [openai:gpt-3.5-turbo]
defaultTest:
options:
provider: openai:gpt-4 # grade responses with gpt-4
tests:
- vars:
user_chat: Hello, how are you?
assert:
- type: llm-rubric
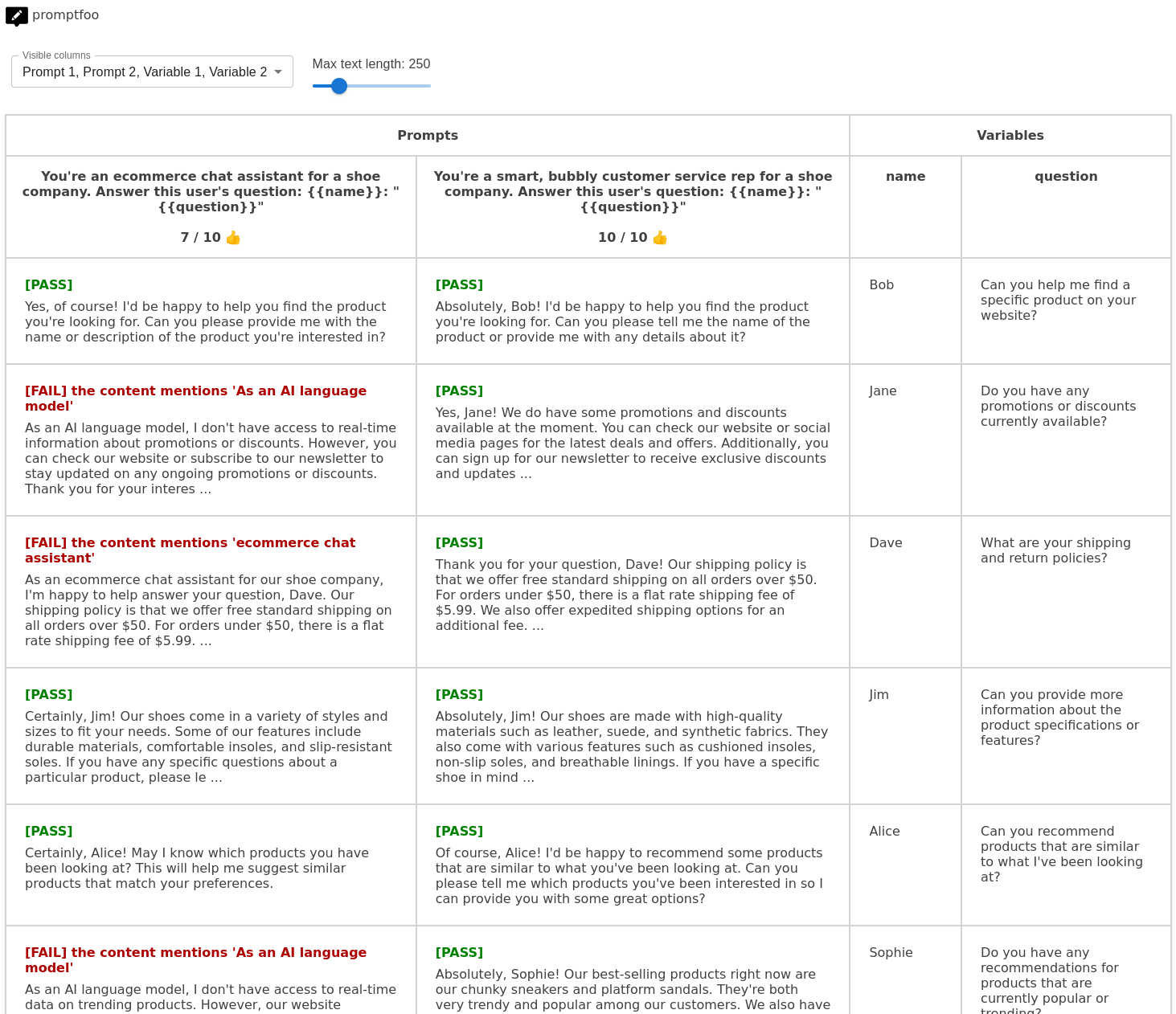
value: Doesn't mention being an AI
- vars:
user_chat: Greet me in Chinese
assert:
- type: llm-rubric
value: is a Chinese greeting
- vars:
user_chat: I am a pineapple
assert:
- type: llm-rubric
value: 1) doesn't reference any fruits besides pineapple, 2) is friendly
Now run the eval with the --grader option set. This will run the eval and mark each test case pass/fail based on the grading rubric:
promptfoo eval
Here's an example self-graded test suite that fails if the AI mentions that it is an AI language model:
Outsource evaluation to other humans
Sometimes you won't be able to evaluate prompts programmatically or with AI. This might be the case if quality evaluation is so subjective that it requires multiple datapoints or special training to evaluate.
In this case, you can outsource rubric grading to human raters. The raters could either score outputs individually, or choose the superior output from a lineup.
Examples of subjective expectations might include:
- Coherence: how well the response flows and maintains logical connections
- Empathy: whether the response shows understanding and compassion
- Tone: whether the output tone conform to some standard
- Values alignment: whether there are signs of bias
After running all the test cases, you can take the test outputs and present them to a human for grading.

How to export prompt candidates and outputs with promptfoo
Assuming you've set up promptfoo and are running promptfoo eval, you can ask human raters to evaluate outputs in two ways:
-
Use the web viewer, which includes a basic interface to rate outputs 👍/👎 on-the-fly:
promptfoo view -
Alternatively, export to a portable format and display results in your desired interface:
promptfoo eval -o results.csvor
promptfoo eval -o results.json
Closing the feedback loop
As a company scales, instead of manually assembling a golden dataset, it can achieve quality a broad range of inputs by collecting test cases from users.
In practice, this means asking users to mark particularly good or bad LLM outputs. For example, collecting 👍/👎 ratings will give you some signal on cases that are particularly interesting or valuable. This has the added bonus of helping you fine-tune a model if that's something you want to do eventually.
What's outlined in this post is one part of a larger system:
- Prompt tuning & evaluation
- Prompt version control
- Continuous integration and deployment
Once a prompt is validated through evaluation, the continuous integration system will release it to a staging or production environment, or a live experiment. Ideally, prompt evaluations become part of our development infrastructure in the same way that unit tests are.
Other prompt engineering principles
Here are some principles that apply to all prompt engineering. They basically boil down to:
- Avoid prompt engineering whenever possible
- Avoid subjective grading criteria whenever possible
Prefer small, testable prompts
Prefer concise prompts that are specific enough to generate a limited range of potential outputs. This helps minimize edge cases and makes it easier to automate evaluation.
With this approach, you can work toward full automation and deploy new prompt changes without worrying about unexpected regressions.
Simplify your evaulation rubric
A simple rubric helps streamline the evaluation process and minimize subjectivity. Focus on the most important criteria for your application and establish clear guidelines for each metric.
Prefer to use programmatic tests, then semantic tests, LLM tests, and lastly human raters.
Fine-tune
When it comes down to it, prompt engineering is not 100% reliable for certain use cases. Fine-tuning allows you to focus more on the overall system and less on tweaking prompts, but it's expensive and requires dedicated resources.
I'm building this
This blog post is just a really long way to say, I haven't found solutions to any of the above in the wild, so I'm building my own.
Check out promptfoo, an open-source toolkit for prompt engineering that implements the process above.
Most notably, it includes a CLI that outputs a matrix view for quickly comparing outputs across multiple prompts, variables, and models. This means that you can easily compare prompts over hundreds or thousands of test cases.
Good luck to everyone prompt engineering out there!

